

















Database Creation and Management
1. Introduction to Databases
A database is an organized collection of data that can be easily accessed, managed, and updated. Databases are used in a wide range of applications to store and retrieve data efficiently. A well-structured database ensures data integrity, security, and scalability for handling complex data structures.
2. Creating a Database
Creating a database involves several steps, including defining its structure, choosing the appropriate data types, and establishing relationships among different entities.
Key Steps in Database Creation:
- Defining the Purpose of the Database: Determine what the database will store and how the data will be used.
- Identifying Tables: Tables are the primary structure for storing data in a relational database. Each table represents an entity.
- Designing Table Structures: Define the fields (columns) in each table along with their data types.
- Populating Data: Enter at least 25 records into the tables for testing and functionality.
3. Table Structure
A table is the backbone of any database. It consists of rows and columns, where each column represents a specific attribute of an entity, and rows represent individual records.
Components of a Table:
- Fields (Columns): Define the attributes of the data, such as
Name,Age, orEmail. - Records (Rows): Represent individual entries in a table.
- Primary Key: A unique identifier for each record in the table.
Example Table Structure:

Data Types:
Data types specify the kind of data a column can hold.
Common Data Types:
- Integer: Whole numbers, e.g.,
Age. - Varchar/String: Text data, e.g.,
Name,Email. - Boolean: True/False values.
- Date/Time: Dates and times.
- Float/Decimal: Numbers with decimals, e.g.,
Price. - Blob: Binary large objects for storing multimedia.
4. Populating Tables
Once the table structure is defined, data is added to populate the database. This ensures the database can be tested for functionality and performance.
Steps to Populate a Table:
- Use SQL
INSERTstatements or database management tools. - Ensure data adheres to field constraints, such as data types and length restrictions.
- Add meaningful and diverse records to represent real-world scenarios.
Example:
INSERT INTO Students (StudentID, Name, Age, Email)
VALUES (1, 'Alice Johnson', 20, 'alice@example.com');
INSERT INTO Students (StudentID, Name, Age, Email)
VALUES (2, 'Bob Smith', 22, 'bob@example.com');
5. Modifying Table Structure
Database requirements evolve over time, necessitating modifications to the table structure. This can include adding new fields, deleting fields, or changing field definitions.
5.1 Adding New Fields:
New fields can be added to accommodate additional data attributes.
Example:
ALTER TABLE Students
ADD Address VARCHAR(255);
5.2 Deleting Fields:
Fields no longer needed can be removed to maintain database efficiency.
Example:
ALTER TABLE Students
DROP COLUMN Address;
5.3 Changing Field Definitions:
Field properties, such as data type or length, can be modified.
Example:
ALTER TABLE Students
MODIFY Age INT(3);
6. Establishing Primary Keys
A primary key is a unique identifier for each record in a table. It ensures that no two rows have the same value in the primary key column.
Characteristics of Primary Keys:
- Must be unique.
- Cannot contain null values.
- Enforces entity integrity.
Defining a Primary Key:
- During Table Creation:
CREATE TABLE Students (
StudentID INT PRIMARY KEY,
Name VARCHAR(100),
Age INT
);
- After Table Creation:
ALTER TABLE Students
ADD PRIMARY KEY (StudentID);
7. Establishing Relationships
Relationships define how tables in a database are connected. They are crucial for maintaining data integrity and minimizing redundancy.
Types of Relationships:
One-to-One:
- Each record in Table A is related to one record in Table B.
- Example: A
Persontable linked to aPassporttable. - Implementation:
CREATE TABLE Person ( PersonID INT PRIMARY KEY, Name VARCHAR(100) ); CREATE TABLE Passport ( PassportID INT PRIMARY KEY, PersonID INT, FOREIGN KEY (PersonID) REFERENCES Person(PersonID) );One-to-Many:
- A record in Table A can be related to multiple records in Table B.
- Example: A
Departmenttable linked to anEmployeestable. - Implementation:
CREATE TABLE Department ( DeptID INT PRIMARY KEY, DeptName VARCHAR(100) ); CREATE TABLE Employees ( EmployeeID INT PRIMARY KEY, DeptID INT, FOREIGN KEY (DeptID) REFERENCES Department(DeptID) );Many-to-Many:
- Records in Table A can be associated with multiple records in Table B and vice versa.
- Example: A
Studentstable linked to aCoursestable via anEnrollmenttable. - Implementation:
CREATE TABLE Students ( StudentID INT PRIMARY KEY, Name VARCHAR(100) ); CREATE TABLE Courses ( CourseID INT PRIMARY KEY, CourseName VARCHAR(100) ); CREATE TABLE Enrollment ( StudentID INT, CourseID INT, PRIMARY KEY (StudentID, CourseID), FOREIGN KEY (StudentID) REFERENCES Students(StudentID), FOREIGN KEY (CourseID) REFERENCES Courses(CourseID) );
Conclusion
Creating and managing databases involves understanding table structures, data types, relationships, and modifications. These components ensure data is organized, consistent, and accessible for various applications. Mastery of these concepts forms the foundation for building robust and scalable database systems.
These notes provide a comprehensive understanding of database creation and management, aligned with Information Technology syllabus standards.
Problem-Solving and Program Design in Information Technology
Introduction to Problem-Solving
Problem-solving in Information Technology (IT) is the process of identifying, analyzing, and resolving challenges using systematic approaches. It is a critical skill for IT professionals, as it lays the foundation for effective program design and the development of reliable software solutions.
Problem-solving involves several stages, each aimed at decomposing complex issues into manageable parts to identify practical solutions. By following structured methodologies, IT professionals ensure that the solutions they implement are efficient, scalable, and maintainable.
Key Concepts in Problem-Solving
1. Definition of a Problem
A problem is a situation that requires a solution to achieve a specific goal. In IT, problems often involve inefficiencies, errors, or unmet requirements in software, systems, or processes.
Effective problem-solving begins with a clear understanding of the problem. This involves:
- Identifying the problem’s scope.
- Determining the stakeholders involved.
- Understanding the goals and constraints.
2. Breaking Down the Problem
To solve a problem effectively, it is essential to decompose it into smaller, more manageable components. This decomposition allows IT professionals to focus on one aspect of the problem at a time, ensuring that each element is addressed systematically.
The primary components of problem decomposition include:
- Input: The data or information provided to the system.
- Process: The operations or actions performed on the input to achieve a desired outcome.
- Output: The result or product of the process.
A widely used tool for representing these components is the IPO Chart (Input-Process-Output Chart), which delineates the relationship between these elements.
3. Systematic Problem-Solving Approaches
Several systematic approaches are commonly used in IT problem-solving, including:
- Algorithm Development: Creating a step-by-step procedure for solving a problem.
- Flowcharting: Using diagrams to visualize the sequence of steps in a process.
- Pseudocode: Writing a simplified, code-like description of a program’s logic.
Steps in Problem-Solving
The problem-solving process in IT typically involves the following steps:
Step 1: Identify the Problem
- Clearly define the problem statement.
- Determine the root cause of the problem.
- Gather all relevant information from stakeholders and systems.
Step 2: Analyze the Problem
- Break down the problem into its significant components (input, process, and output).
- Examine the constraints and requirements.
- Use tools like cause-and-effect diagrams or flowcharts for better understanding.
Step 3: Design a Solution
- Brainstorm potential solutions and evaluate their feasibility.
- Develop algorithms or procedures that address the problem.
- Create an IPO Chart to map out the solution structure.
Step 4: Implement the Solution
- Translate the designed solution into code using appropriate programming languages.
- Test the implementation to ensure it works as intended.
- Debug and optimize the code for performance and reliability.
Step 5: Evaluate the Solution
- Assess whether the solution meets the problem’s requirements.
- Collect feedback from stakeholders.
- Make necessary adjustments or improvements.
Program Design Principles
Program design is the process of planning and creating software that solves specific problems or fulfills user needs. It emphasizes clarity, efficiency, and maintainability to ensure that the program meets its objectives.
1. Understanding the Problem
Before designing a program, it is essential to thoroughly understand the problem it aims to solve. This involves:
- Identifying the target audience.
- Understanding the program’s purpose and scope.
- Considering constraints such as time, budget, and resources.
2. Algorithm Development
Algorithms form the backbone of program design. An algorithm is a set of instructions that define how a problem is solved step-by-step. Effective algorithms should be:
- Accurate: They must produce the correct output for all valid inputs.
- Efficient: They should minimize resource usage (time and space).
- Readable: They should be easy to understand and modify.
3. Tools for Program Design
Several tools and techniques are used in program design, including:
- Flowcharts: Visual representations of processes, showing the sequence of steps using symbols such as rectangles (processes), diamonds (decisions), and arrows (flow direction).
- Pseudocode: A plain-language description of a program’s logic, bridging the gap between human understanding and machine code.
- Modular Design: Dividing the program into smaller, self-contained modules, each responsible for a specific task. This promotes reusability and simplifies debugging.
4. Data Structures and Algorithms
Selecting the right data structures and algorithms is crucial for efficient program design. Common data structures include:
- Arrays: For storing sequences of elements.
- Linked Lists: For dynamic memory allocation.
- Stacks and Queues: For managing data in specific orders.
- Trees and Graphs: For hierarchical and networked relationships.
5. Validation and Testing
Once the program is designed and implemented, it must be tested rigorously to ensure:
- It meets all functional requirements.
- It handles edge cases and invalid inputs gracefully.
- It performs efficiently under various conditions.
The Role of IPO Charts
IPO Charts (Input-Process-Output Charts) are essential tools for problem-solving and program design. They provide a structured way to represent the key components of a problem and its solution.
1. Components of an IPO Chart
- Input: The data required to solve the problem.
- Process: The steps or operations performed on the input to produce the desired outcome.
- Output: The result or product generated by the process.
2. Benefits of IPO Charts
- Simplifies complex problems by breaking them down into fundamental components.
- Enhances understanding of the relationship between inputs, processes, and outputs.
- Serves as a reference during the implementation phase.
3. Example IPO Chart
For a program that calculates the average of three numbers:

Common Challenges in Problem-Solving and Program Design
1. Understanding Requirements
Misinterpreting requirements can lead to incorrect solutions. It is vital to:
- Communicate effectively with stakeholders.
- Use techniques like user stories and requirement specifications.
2. Managing Complexity
Large problems can be overwhelming. Strategies to manage complexity include:
- Modular design.
- Iterative development.
- Use of abstraction and encapsulation.
3. Debugging and Testing
Errors in code can lead to unexpected behavior. Debugging tools and systematic testing approaches (unit testing, integration testing, etc.) are essential for identifying and fixing issues.
4. Optimizing Performance
Programs must be optimized for speed and resource usage. This requires:
- Selecting efficient algorithms.
- Avoiding redundant computations.
- Profiling code to identify bottlenecks.
Conclusion
Problem-solving and program design are foundational skills in Information Technology. By decomposing problems into significant components, IT professionals can create structured, efficient, and reliable solutions. The use of tools like IPO Charts, flowcharts, and pseudocode enhances clarity and facilitates the transition from problem analysis to program implementation. Through systematic approaches and continuous testing, IT professionals can ensure that their solutions meet user needs and perform optimally in diverse scenarios.
Variables and Constants
Distinguishing Between Variables and Constants
In computer programming, the concepts of variables and constants are fundamental. They serve as building blocks for storing and managing data within a program.
Let us explore each in detail:
What are Variables?
Variables are symbolic names or identifiers used to store data values in a program. The value stored in a variable can change during the execution of a program. Variables act as placeholders in memory where data is stored temporarily for use during computation or processing.
- Definition: A variable is an area of storage whose value can change during program execution.
- Characteristics:
- Variables are dynamic; their values can be updated as the program runs.
- Each variable has a specific data type (e.g., integer, string) that defines the kind of value it can store.
- Variables must be declared before use in some programming languages (e.g., C, Java).
- Example in Python:
x = 10 # Variable x is assigned the value 10 print(x) # Output: 10 x = 20 # Variable x is reassigned a new value print(x) # Output: 20
What are Constants?
Constants, on the other hand, are immutable values. Once assigned, the value of a constant cannot be changed during the program’s execution. Constants provide a reliable way to store values that remain the same throughout the program.
- Definition: A constant is a value that does not change during program execution.
- Characteristics:
- Constants are fixed and cannot be modified after their initial declaration.
- They are often used for values that are universally true within a program (e.g., mathematical constants like Pi).
- Example in Python:
PI = 3.14159 # PI is a constant print(PI) # Output: 3.14159Note: By convention, constants are often written in uppercase letters to distinguish them from variables.
Key Differences Between Variables and Constants

Data Types
Data types define the kind of values a variable or constant can store. Each programming language provides a variety of data types, which can broadly be categorized as follows:
1. Integers
Integers are whole numbers, both positive and negative, including zero. They do not have decimal points.
- Example:
5, -42, 0 - Uses: Counting, indexing, and performing arithmetic operations.
- In Python:
age = 25 # age is an integer print(type(age)) # Output: <class 'int'>
2. Floating Point (Real Numbers)
Floating-point numbers represent real numbers that include decimal points. They can store fractional values.
- Example:
3.14, -0.001, 2.0 - Uses: Scientific calculations, measurements, and precise arithmetic.
- In Python:
pi = 3.14159 # pi is a floating-point number print(type(pi)) # Output: <class 'float'>
3. Characters
Characters represent individual letters, digits, or symbols. They are typically stored in single quotes in many programming languages.
- Example:
'A', '9', '@' - Uses: Representing textual or symbolic information.
- In Python:
letter = 'A' # letter is a character print(type(letter)) # Output: <class 'str'>Note: In Python, characters are stored as strings of length 1.
4. Boolean
Boolean data types represent truth values: True or False.
- Uses: Logical operations, decision-making, and conditional statements.
- In Python:
is_valid = True # is_valid is a boolean print(type(is_valid)) # Output: <class 'bool'>
5. String
Strings are sequences of characters used to represent text.
- Example:
"Hello", "123", "@!#" - Uses: Displaying messages, storing names, and manipulating textual data.
- In Python:
name = "Alice" # name is a string print(type(name)) # Output: <class 'str'>
Importance of Variables and Constants in Programming
Variables
- Dynamic Storage: Variables allow programs to dynamically store and process data.
- Flexibility: Since variables can change, they enable versatile and interactive programs.
- Examples in Use:
- Storing user input.
- Tracking scores in a game.
- Managing intermediate results in calculations.
Constants
- Stability: Constants ensure certain values remain unchanged throughout execution, reducing errors.
- Readability: They make programs easier to read and understand by providing meaningful names to fixed values.
- Examples in Use:
- Representing mathematical constants like
PI. - Defining configuration values (e.g., maximum retries).
- Specifying constant strings (e.g.,
"ERROR").
- Representing mathematical constants like
Common Mistakes and Best Practices
For Variables:
- Mistake: Using ambiguous variable names (e.g.,
x,yinstead ofage,score). - Best Practice: Use descriptive names that indicate the purpose of the variable.
temperature = 98.6 # Good practice t = 98.6 # Poor practice - Mistake: Forgetting to initialize variables before use.
- Best Practice: Always initialize variables to avoid undefined behavior.
count = 0 # Initialize before using
For Constants:
- Mistake: Accidentally modifying constants in code.
- Best Practice: Use naming conventions (e.g., uppercase) to indicate constants.
- Mistake: Hardcoding values instead of using constants.
- Best Practice: Define constants to avoid repetitive code.
DISCOUNT_RATE = 0.10 # Define constant price = 100 - (100 * DISCOUNT_RATE)
Conclusion
Understanding variables and constants is essential for effective programming. Variables provide the flexibility to work with changing data, while constants offer stability for fixed values. Choosing the right data type and following best practices ensures robust and efficient code. As you continue learning programming, keep exploring how these concepts are implemented in different languages and applied in real-world scenarios.
Problem-Solving and Program Design
Problem-solving and program design are foundational skills in information technology and computer science. These skills enable individuals to design effective solutions to computational problems, often expressed as algorithms, flowcharts, or pseudocode. By mastering these techniques, developers can build reliable, efficient, and user-friendly software systems.
1. Representing Algorithms in Flowcharts and Pseudocode
Flowchart Representation
A flowchart is a graphical representation of a process or algorithm. It uses standard symbols to represent various types of operations and the flow of control within the algorithm. Flowcharts make it easier to visualize the logic and structure of a program before writing code.
Key Flowchart Symbols
Input/Output Symbol (Parallelogram): Represents operations involving input (e.g., reading data) or output (e.g., displaying results).
- Example: “Input user’s age” or “Display the sum.”
Process Symbol (Rectangle): Represents a process or an operation that needs to be performed.
- Example: “Calculate the total” or “Store the result in a variable.”
Decision Symbol (Diamond): Represents a decision-making step where a condition is checked, and the flow branches based on the result.
- Example: “Is X greater than Y?”
Directional Arrows: Indicate the flow of control from one step to another.
- Arrows connect the symbols to show the sequence of operations.
Start/Stop Symbol (Oval): Represents the beginning or end of a process.
- Example: “Start the program” or “Stop the program.”
Advantages of Flowcharts
- Simplifies complex processes.
- Enhances understanding of algorithms.
- Provides a clear visual representation for debugging and analysis.
Pseudocode Representation
Pseudocode is a textual representation of an algorithm written in a structured but plain language that resembles programming. It focuses on the logic rather than syntax, making it language-independent.
Key Elements of Pseudocode
Input/Output:
InputorRead: Indicates data to be entered into the system.- Example:
Input Age
- Example:
Output,Display, orPrint: Represents data to be displayed or printed.- Example:
Print "Total is:" Total
- Example:
Processes:
- Operations like calculations, storing values, or modifying variables.
- Example:
Sum = A + B
- Example:
- Operations like calculations, storing values, or modifying variables.
Conditional Branching:
If-Then: Executes a block of statements if a condition is true.- Example:
If Score > 50 Then Print "Pass" End If
- Example:
If-Then-Else: Provides alternate execution paths based on a condition.- Example:
If Age >= 18 Then Print "Adult" Else Print "Minor" End If
- Example:
- Nested Conditions: Conditions within conditions for complex logic.
Loops:
- Used to repeat a block of statements.
- For Loop: Iterates a specific number of times.
For i = 1 to 10 Print i End For - While Loop: Repeats as long as a condition is true.
While Count < 5 Print Count Count = Count + 1 End While - Repeat Until Loop: Repeats until a condition becomes true.
Repeat Input Number Until Number > 0
- For Loop: Iterates a specific number of times.
- Used to repeat a block of statements.
2. Relational Operators
Relational operators compare two values and determine the relationship between them. They are commonly used in decision-making and control structures.
- Less than (
<): True if the left operand is smaller than the right. - Greater than (
>): True if the left operand is larger than the right. - Equal to (
=): True if both operands are equal. - Less than or equal to (
<=): True if the left operand is smaller or equal to the right. - Greater than or equal to (
>=): True if the left operand is larger or equal to the right. - Not equal to (
<>): True if the operands are not equal.
Examples:
If Marks >= 50 Then Print "Pass"If A <> B Then Print "Values are different"
3. Logical Operators
Logical operators are used to combine or modify conditions in decision-making. They play a critical role in building complex logical expressions.
Types of Logical Operators
AND:
- True if both conditions are true.
- Example:
If Age >= 18 AND Citizenship = "Yes" Then Print "Eligible to vote" End If
OR:
- True if at least one condition is true.
- Example:
If Temperature < 0 OR Weather = "Snowing" Then Print "Wear a coat" End If
NOT:
- Negates the condition, making true conditions false and vice versa.
- Example:
If NOT (IsRaining) Then Print "Go for a walk" End If
Truth Tables
Truth tables are used to represent the outcome of logical operations for all possible input values.

4. Arithmetic Operators
Arithmetic operators perform basic mathematical operations.
Types of Arithmetic Operators
- Addition (
+): Adds two numbers.- Example:
Sum = A + B
- Example:
- Subtraction (
-): Subtracts one number from another.- Example:
Difference = A - B
- Example:
- Multiplication (
*): Multiplies two numbers.- Example:
Product = A * B
- Example:
- Division (
/): Divides one number by another.- Example:
Quotient = A / B
- Example:
- Modulus (
MOD): Returns the remainder of a division operation.- Example:
Remainder = A MOD B
- Example:
- Integer Division (
DIV): Returns the integer part of a division operation.- Example:
Result = A DIV B
- Example:
5. Applications of Problem-Solving Techniques
Step-by-Step Approach to Problem-Solving
- Define the Problem: Clearly state the problem to be solved.
- Analyze Requirements: Identify inputs, outputs, and processing requirements.
- Design the Algorithm: Develop the logical steps using flowcharts or pseudocode.
- Implement the Solution: Convert the design into actual code.
- Test and Debug: Verify that the solution works as expected and fix errors.
Practical Example
Problem: Calculate the sum of all even numbers from 1 to N.
Solution (Pseudocode):
Input N
Sum = 0
For i = 1 to N
If i MOD 2 = 0 Then
Sum = Sum + i
End If
End For
Print "Sum of even numbers is:" Sum
Solution (Flowchart):
- Start
- Input N
- Initialize Sum to 0
- Loop from 1 to N
- Check if the number is even (i MOD 2 = 0)
- If True, add it to Sum
- End Loop
- Output the Sum
- Stop
Conclusion
Mastering the techniques of algorithm representation, logical reasoning, and arithmetic computation is essential for efficient problem-solving in programming. Flowcharts provide a clear visual guide, while pseudocode offers a structured textual plan for implementation. By combining these tools with relational and logical operators, developers can address complex problems systematically.
Testing Algorithms for Correctness
Testing algorithms for correctness ensures that they produce the expected outputs for given inputs. This process is crucial in the development and maintenance of software systems and involves systematically verifying that an algorithm functions as intended in all scenarios.
Below are key concepts and techniques used in testing algorithms:
1. Importance of Testing Algorithms
- Error Detection: Identifies logical, syntax, or runtime errors in the algorithm.
- Validation: Confirms that the algorithm meets the specified requirements and objectives.
- Optimization: Helps refine the algorithm to improve performance and efficiency.
- Reliability: Ensures consistent and predictable behavior of the algorithm under various conditions.
2. Techniques for Testing Algorithms
a. Dry Runs
A dry run involves manually simulating the execution of an algorithm using pen and paper to understand its behavior. It helps to:
- Identify logical errors without using a computer.
- Ensure clarity in the algorithm’s logic.
b. Desk Checks
Desk checks involve the use of trace tables to monitor the values of variables during each step of the algorithm’s execution. This technique provides insight into:
- The flow of control through the algorithm.
- Intermediate values and how they contribute to the final output.
c. Debugging
Debugging is a systematic process of locating and fixing errors in the algorithm. Common debugging tools include:
- Print Statements: To display the values of variables during execution.
- Debugging Software: Tools integrated into programming environments that allow step-by-step execution.
d. Test Cases
Developing test cases ensures that the algorithm is tested under various conditions. Test cases can be:
- Normal Test Cases: With typical inputs that the algorithm is expected to handle.
- Boundary Test Cases: To test the algorithm’s behavior at the limits of its input range.
- Invalid Test Cases: With erroneous inputs to check the robustness of error handling.
e. Unit Testing
This involves testing individual components or functions of the algorithm in isolation to ensure their correctness.
f. Integration Testing
After testing individual components, integration testing ensures that all parts of the algorithm work together seamlessly.
3. Steps in Testing an Algorithm
- Step 1: Understand the Problem: Define the problem the algorithm aims to solve.
- Step 2: Develop Test Cases: Identify input-output pairs for validation.
- Step 3: Execute the Algorithm: Perform a dry run or use a programming language.
- Step 4: Compare Outputs: Match the actual output with the expected output.
- Step 5: Refine the Algorithm: Debug and improve the algorithm as needed.
4. Common Errors in Algorithms
- Syntax Errors: Mistakes in the code that prevent execution.
- Logical Errors: Errors in the logic that produce incorrect results.
- Runtime Errors: Errors that occur during execution, such as division by zero.
- Semantic Errors: Misinterpretation of the problem requirements.
Desk Checks/Dry Runs
A desk check or dry run is a manual process of verifying an algorithm’s correctness. It involves simulating the algorithm step-by-step to trace the flow of data and logic. Below are detailed notes on desk checks and trace tables:
1. Desk Checks Desk checks are performed without executing the algorithm on a computer. They are particularly useful in:
- Understanding how the algorithm processes data.
- Identifying errors in the logic or design of the algorithm.
- Gaining insights into the algorithm’s behavior before implementation.
2. Trace Tables Trace tables are a tool used during desk checks to monitor the state of variables at each step of the algorithm.
They are constructed as follows:
a. Components of a Trace Table
- Column Headings: Represent variable names or identifiers.
- Rows: Represent the values of variables during each step or iteration.
- Additional Columns: May include conditions for decision-making (e.g., results of Boolean expressions).
b. Purpose of Trace Tables
- Provide a clear view of the algorithm’s flow.
- Identify points where errors or unexpected behaviors occur.
- Verify the correctness of loops, conditionals, and calculations.
c. Example of a Trace Table For the following algorithm:
Initialize sum = 0
For i = 1 to 5
sum = sum + i
End For
Output sum
The trace table would look like this:

At the end of the algorithm, the value of sum is 15, which is output as the result.
d. Steps to Construct and Use a Trace Table
- Step 1: Identify Variables: List all variables and their initial values.
- Step 2: Add Columns for Variables: Create a column for each variable and conditions if applicable.
- Step 3: Trace Each Step: Record the values of variables for each step or iteration.
- Step 4: Analyze the Table: Verify that the outputs match the expected results.
3. Benefits of Desk Checks and Trace Tables
- Provide a systematic way to understand and debug algorithms.
- Enhance problem-solving skills by simulating the execution flow.
- Save time and resources by identifying errors before coding.
4. Common Scenarios for Desk Checks
- Algorithms with loops and iterations.
- Complex conditional statements and decision-making processes.
- Algorithms involving mathematical computations.
- Verifying edge cases or boundary conditions.
5. Limitations of Desk Checks
- Time-consuming for complex algorithms with numerous variables.
- Prone to human error, especially in large trace tables.
- Not a substitute for actual implementation and testing on a computer.
6. Best Practices for Desk Checks
- Use small, manageable test cases to reduce complexity.
- Double-check calculations and logic at each step.
- Collaborate with peers to identify errors and refine the algorithm.
7. Tools to Assist Desk Checks While desk checks are typically manual, some tools can assist in creating and managing trace tables, such as spreadsheet software (e.g., Microsoft Excel, Google Sheets).
Conclusion
Testing algorithms for correctness and performing desk checks with trace tables are foundational techniques in problem-solving and program design. They not only ensure that algorithms function as intended but also enhance understanding of the underlying logic and flow. By mastering these techniques, students and professionals can develop more reliable, efficient, and effective algorithms.
Low-Level and High-Level Programming Languages
Programming Languages
A programming language is a formal set of instructions that a computer can understand and execute. These languages allow programmers to write software, control hardware, and develop applications by defining algorithms and manipulating data. Programming languages are broadly categorized into low-level and high-level languages based on their abstraction level and proximity to machine code.
Low-Level Programming Languages
Definition
Low-level programming languages operate close to the hardware and provide minimal abstraction from the machine’s instruction set architecture. They directly interact with a computer’s central processing unit (CPU) and memory, making them highly efficient but challenging for humans to read and write.
Types of Low-Level Languages
- Machine Language (First-Generation Language)
- Description: Machine language consists of binary code (0s and 1s) that the computer’s CPU directly understands. It is the most basic form of programming and represents the hardware instructions.
- Features:
- Written in binary or hexadecimal.
- CPU-specific and not portable across different hardware architectures.
- Extremely fast and efficient as it executes without translation.
- Examples:
- Binary code:
10101011 00001111
- Binary code:
- Advantages:
- Maximum control over hardware.
- Fastest execution speed since no translation is needed.
- Disadvantages:
- Difficult to write, debug, and maintain.
- Tedious and error-prone.
- Assembly Language (Second-Generation Language)
- Description: Assembly language uses mnemonic codes to represent machine instructions. It provides a symbolic representation of the machine code, making it slightly easier for humans to understand.
- Features:
- Requires an assembler to convert into machine code.
- Still CPU-specific and non-portable.
- Provides direct access to hardware and system resources.
- Examples:
MOV AL, 1(moves the value 1 into the AL register).
- Advantages:
- Easier to understand than binary.
- High performance and control over hardware resources.
- Disadvantages:
- Still complex and not suitable for large-scale applications.
- Limited abstraction makes it hard to debug.
Characteristics of Low-Level Languages
- Minimal Abstraction: These languages closely reflect the hardware’s functionality.
- Hardware-Specific: Programs are tailored for specific processors or hardware.
- Efficient Execution: Programs execute quickly due to the lack of translation overhead.
- Complexity: They are difficult to learn, write, and maintain, requiring knowledge of computer architecture.
High-Level Programming Languages
Definition
High-level programming languages provide greater abstraction from the hardware, allowing programmers to focus on logic and functionality rather than intricate hardware details. These languages are designed to be human-readable and portable across different systems.
Features of High-Level Languages
- Use of English-like Syntax: Commands and statements are similar to natural language (e.g.,
if,for,while). - Portability: Code written in high-level languages can be executed on multiple platforms with minimal modifications.
- Ease of Debugging: Tools like debuggers and compilers simplify error detection.
- Abstraction: Complex operations are encapsulated into simple commands or functions.
Types of High-Level Languages
Procedural Languages
- Focus on step-by-step instructions to achieve a task.
- Example: C, Pascal.
Object-Oriented Languages
- Use objects and classes to organize code and data.
- Example: Java, C++, Python.
Functional Languages
- Focus on mathematical functions and immutability.
- Example: Haskell, Lisp.
Scripting Languages
- Used for automating tasks and managing applications.
- Example: Python, JavaScript.
Markup Languages
- Primarily used for data formatting and presentation.
- Example: HTML, XML.
Examples of High-Level Languages
- Visual Basic:
- A beginner-friendly language used for developing Windows applications.
- Pascal:
- Used for teaching structured programming.
- C:
- Combines the efficiency of low-level programming with high-level syntax.
Advantages of High-Level Languages
- Ease of Use: Readable and intuitive syntax makes programming accessible.
- Error Reduction: High-level languages have built-in error checking and debugging tools.
- Productivity: Programmers can write complex applications quickly.
- Portability: Programs can run on different hardware and operating systems with minimal changes.
Disadvantages of High-Level Languages
- Performance Overhead: Programs are slower than those written in low-level languages due to translation layers (e.g., compilers, interpreters).
- Limited Control: Developers cannot directly manipulate hardware or system resources.
Comparing Low-Level and High-Level Languages
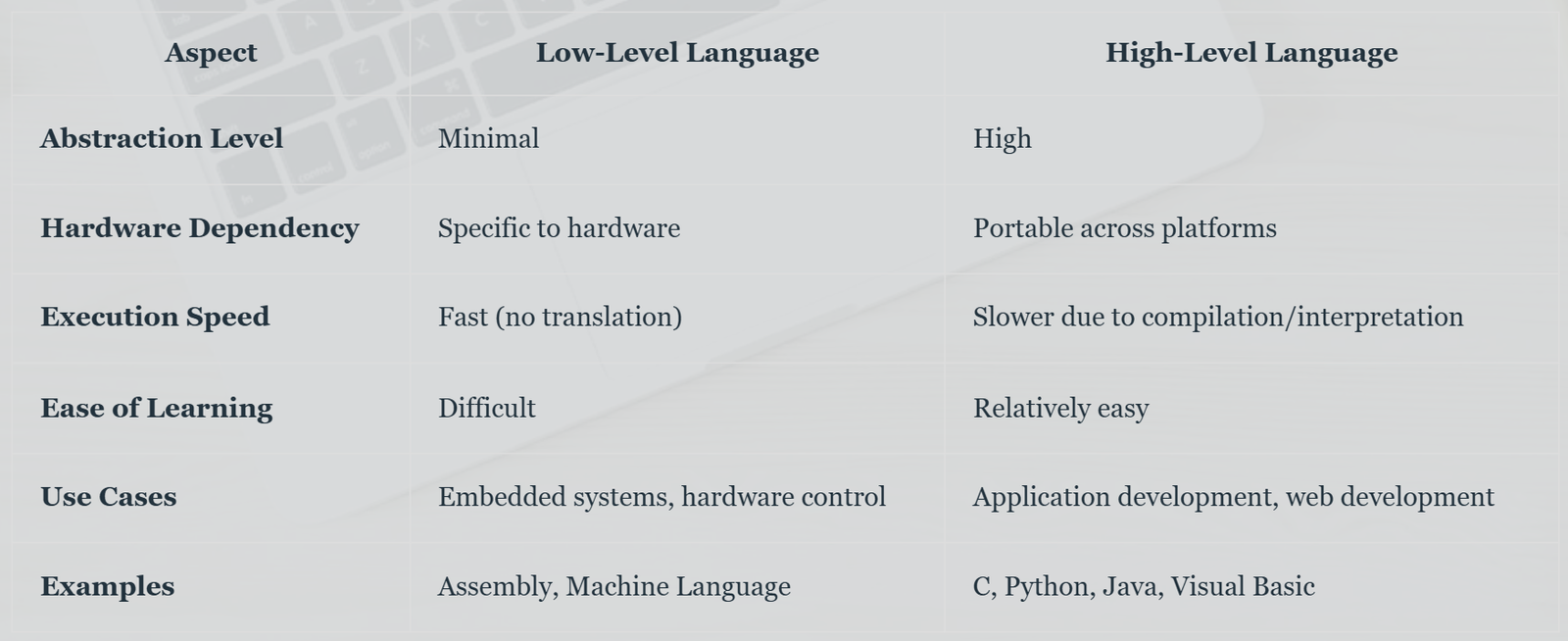
Role of Translators in Programming
High-level programs need to be translated into machine code for execution. Translators are tools that perform this task.
Types of Translators
Compilers
- Convert entire source code into machine code before execution.
- Example: GCC for C/C++.
Interpreters
- Translate and execute code line-by-line.
- Example: Python Interpreter.
Assemblers
- Convert assembly language into machine code.
- Example: MASM (Microsoft Macro Assembler).
Factors to Consider When Choosing a Language
- Performance Needs: Low-level languages are preferable for performance-critical tasks.
- Portability: High-level languages are ideal for cross-platform compatibility.
- Project Complexity: High-level languages simplify development for complex applications.
- Developer Expertise: Low-level programming requires a deep understanding of hardware.
Applications of Low-Level and High-Level Languages
Low-Level Languages
- Writing device drivers.
- Programming embedded systems (e.g., microcontrollers, IoT devices).
- Game engine optimization.
High-Level Languages
- Web and mobile application development.
- Scientific computing and data analysis.
- Enterprise software and database systems.
Future of Programming Languages
Advances in technology have blurred the lines between low-level and high-level languages. Modern tools and compilers optimize high-level code to achieve performance close to low-level programming. Additionally, new paradigms like quantum programming and artificial intelligence influence the evolution of programming languages.
Declaring Variables and Constants Using Elementary Data Types
In programming, variables and constants are essential components that store data. A clear understanding of elementary data types is crucial to ensure accurate and efficient program execution. Here’s an in-depth explanation of these concepts.
1. Variables
A variable is a storage location in memory that holds data, which can be modified during program execution. Variables are defined by:
- Data type: Specifies the kind of data the variable can hold (e.g., integer, string).
- Name/Identifier: A unique name to reference the variable in the program.
Declaration of Variables
To declare a variable:
- Specify its data type.
- Assign a name to the variable.
- Optionally, initialize it with a value.
Syntax Examples:
- In Python:
age = 25 # Implicit declaration with initialization - In Java:
int age = 25; // Explicit declaration with initialization - In C:
int age = 25; // Explicit declaration with initialization
2. Constants
A constant is a value that does not change during program execution. Constants are helpful for fixed values, such as PI or tax rates, and improve code readability and maintainability.
Declaration of Constants
To declare a constant:
- Use a keyword like
final,const, or similar, depending on the programming language. - Assign a fixed value to it.
Examples:
- In Python:
PI = 3.14159 # Conventionally uppercase to indicate a constant - In Java:
final double PI = 3.14159; - In C:
#define PI 3.14159
3. Elementary Data Types
Elementary data types are the building blocks for declaring variables and constants. They are categorized based on the kind of data they store:
Integer (int)
- Used to store whole numbers, both positive and negative.
- Range depends on the system and programming language.
- Example:
int count = 10; // In Java - Storage size:
- Typically 4 bytes in most programming languages.
Real/Double/Float
- Used for decimal or floating-point numbers.
- Double provides more precision than float.
- Example:
float temperature = 36.6f; // Float in Java double pi = 3.14159; // Double in Java - Storage size:
- Float: 4 bytes
- Double: 8 bytes
Character (char)
- Stores a single character or symbol.
- Enclosed in single quotes (e.g.,
'A'). - Example:
char grade = 'A'; // In Java - Storage size:
- Typically 1 byte.
String
- Stores a sequence of characters.
- Example:
name = "John Doe" # In Python - In some languages like C, strings are arrays of characters ending with a null character (
\0).
Boolean/Logical
- Stores one of two values:
trueorfalse. - Example:
boolean isActive = true; // In Java
- Stores one of two values:
4. Key Concepts in Data Types
Type Casting
- Converting one data type into another (e.g., integer to float).
- Example:
int x = 10; double y = (double) x; // Explicit casting
Type Inference
- Some languages (like Python) infer the data type based on the value assigned.
- Example:
count = 10 # Automatically inferred as an integer
Type Safety
- Ensures variables hold data of the declared type.
- Example:
int age = "twenty"; // Error in Java
5. Guidelines for Naming Variables and Constants
- Use meaningful names (e.g.,
age,temperature). - Avoid reserved keywords.
- Follow language conventions:
- CamelCase for variables in Java (
userName). - Uppercase for constants (
PI).
- CamelCase for variables in Java (
6. Practical Use Cases
- Integer: Counting items, storing ages, etc.
- Float/Double: Storing precise measurements like temperature.
- Character: Representing grades or single symbols.
- String: Representing names or messages.
- Boolean: Storing true/false conditions.
7. Memory Allocation
- Static: Fixed memory allocation during compile-time.
- Dynamic: Flexible memory allocation during runtime.
Programming Language Comparison

Exercises for Practice
- Declare variables of all elementary data types in your preferred language.
- Write a program to calculate the area of a circle using constants.
- Practice type casting between integer and float.
Program Implementation
Program implementation is a critical stage in software development where algorithmic statements are translated into high-level programming language constructs. This phase ensures that the logical steps devised during the problem-solving process are represented in a format understandable by computers. The process involves various fundamental concepts that programmers need to master, such as assignment statements, input/output operations, syntax for operators, conditional branching, and iteration. Each of these concepts is elaborated below.
Assignment Statements
Assignment statements are used to store values in variables. They form the basis of any program, allowing the programmer to manage and manipulate data. An assignment statement typically consists of a variable, an assignment operator (e.g., =), and a value or expression to be assigned.
Example:
x = 10 # Assigning the value 10 to the variable x
name = "Alice" # Assigning the string "Alice" to the variable name
sum = a + b # Assigning the result of the expression a + b to the variable sum
Key Points:
- The left-hand side must always be a variable.
- The right-hand side can be a constant, variable, or expression.
- Assignment operators differ across languages (e.g.,
=in Python and Java,:=in Pascal).
Input/Output Operations
Input and output (I/O) operations allow a program to interact with users and external systems. These operations facilitate reading data entered by a user via a keyboard or displaying results on a monitor.
Input Operations
Input operations capture data from users and store it in variables. In most programming languages, specific functions or methods handle input.
Examples:
Python:
name = input("Enter your name: ") # Captures user input as a string age = int(input("Enter your age: ")) # Converts input into an integerC++:
int age; cout << "Enter your age: "; cin >> age; // Captures input and stores it in the variable age
Output Operations
Output operations display information to the user. They include printing variables, strings, or computed results.
Examples:
Python:
print("Hello, World!") # Prints a string print("Your age is:", age) # Prints a string and a variableC++:
cout << "Hello, World!" << endl; // Prints a string and moves to a new line cout << "Your age is: " << age << endl; // Prints a string and a variable
Key Points:
- Ensure proper data types for input (e.g., converting strings to integers if necessary).
- Outputs should be formatted for clarity.
Syntax for Arithmetic, Logic, and Relational Operators
Operators are symbols or keywords that perform operations on variables and values. These include arithmetic, logical, and relational operators, each serving distinct purposes.
Arithmetic Operators
Arithmetic operators are used to perform mathematical operations on numeric data types.

Logical Operators
Logical operators are used to combine or negate conditions, returning Boolean values (true/false).

Relational Operators
Relational operators compare values and return Boolean results.

Key Points:
- Ensure proper operator precedence (e.g., multiplication and division before addition and subtraction).
- Use parentheses to clarify complex expressions.
Syntax for Conditional Branching
Conditional branching allows a program to make decisions based on specific conditions. Common structures include if, if-else, nested if, and case statements.
Simple If Statement
Executes a block of code if a condition evaluates to true.
if condition:
# Code to execute
If-Else Statement
Provides an alternative code block if the condition evaluates to false.
if condition:
# Code if condition is true
else:
# Code if condition is false
Nested If-Else
Allows for multiple levels of decision-making.
if condition1:
# Code if condition1 is true
elif condition2:
# Code if condition2 is true
else:
# Code if neither condition1 nor condition2 is true
Case or Switch Statements
Used for multiple fixed value checks (available in languages like C++ and Java).
switch(expression) {
case value1:
// Code for value1
break;
case value2:
// Code for value2
break;
default:
// Code if no case matches
}
Key Points:
- Indentation is critical in languages like Python.
- Always include a default case in switch statements for unhandled inputs.
Syntax for Iteration (Loops)
Iteration allows repetitive execution of a block of code. Common loop structures include for, while, and repeat loops.
For Loop
Executes a block of code a fixed number of times.
for i in range(5):
print(i) # Prints numbers 0 to 4
While Loop
Executes a block of code as long as a condition is true.
while condition:
# Code to execute
# Update condition to avoid infinite loops
Repeat/Do-While Loop
Executes a block of code at least once, then repeats as long as the condition is true (used in languages like C++).
do {
// Code to execute
} while (condition);
Key Points:
- Avoid infinite loops by ensuring conditions eventually evaluate to false.
- Use
breakandcontinuestatements for better loop control.
Conclusion
Understanding the translation of algorithmic statements into high-level programming syntax is fundamental for successful program implementation. Mastery of assignment statements, I/O operations, operators, conditional branching, and loops enables developers to create efficient, error-free programs. By practicing these concepts, programmers can build robust solutions to complex problems.